95 Contoh Script Iklan Radio Monolog
contoh script iklan radio monolog

Nov 01, 2019 · Tugas Produksi iklan media TV dan Radio Berbagi Dapatkan link; Facebook; Twitter; Pinterest; Email; Aplikasi Lainnya; November 01, 2019 Naskah iklan Radio Dialog dan Monolog CONTOH NASKAH IKLAN RADIO . Naskah Iklan Dialog . Produk : Baygon. Durasi : 30 detik . SFx : Suara nyamuk. Ritin ... Naskah iklan Monolog … 0
Untuk itu, berikut ini beberapa contoh naskah iklan radio produk komersial yang lucu untuk makanan dan minuman coba dituliskan berikut ini : Contoh Naskah Iklan Radio Komersial. Iklan Deterjen Soso. Iklan Sabun “FamFamous”. Iklan Sabun Beauty. Contoh Naskah Iklan Radio Lucu. Iklan … 1

May 29, 2021 · Contoh Iklan Media Radio Untuk Iklan Layanan Masyarakat. Adik : Wah ada makan nih. (Tangan mendekati makanan untuk diambil) Ibu : Eittt, cuci tangan dulu adik. (Sambil … 2

Skrip Iklan Radio – DIKBUD 3
Contoh Script Iklan Di Radio - Dunia Belajar 4

Skrip Iklan Radio – DIKBUD 5
Script Iklan Radio 6
Mar 16, 2016 · Gak enak badan /??minum BIO7 membantu memelihara daya tahan tubuh anda. “Di kocok-kocok lalu diminum” (dibawakan dengan nyanyi) BIO7 JAMU TETESNYA ORANG INDONESIA. Informasi lebih lanjut hubungi: 082317001000. SKRIP IKLAN MONOLOG… 7

√Iklan Elektronik - gurune.net 8
Script Iklan Radio 9

Contoh Naskah Drama Radio - Aneka Contoh 10
Berikut Contoh Script Opening Untuk Siaran Radio Program Request 11

Contoh Teks Penyiar Radio – retorika 12

(DOC) SINOPSIS IKLAN LAYANAN MASYARAKAT rokok | darall mesya - Academia.edu 13
Contoh Naskah Talk Show - Aneka Macam Contoh 14

Contoh Script Iklan Produk Di Radio - Contoh Kono 15

Contoh Teks Drama Tradisional – mosi 16
Berikut Contoh Script Opening Untuk Siaran Radio Program Request 17

Produksi program siaran radio 18

Naskah Iklan Elektronik - Dunia Sekolah ID 19
script iklan layanan masyarakat 20

Contoh Naskah Iklan Radio Lucu - Contoh Resource 21
![Berikut Contoh Script Opening Untuk Siaran Radio Program Request - [PDF Document]](https://static.fdokumen.com/img/1200x630/reader017/html5/js20200116/5e1f5db294e17/5e1f5db305fa0.png?t=1627927209)
Berikut Contoh Script Opening Untuk Siaran Radio Program Request - [PDF Document] 22

Contoh Naskah Drama Radio - Contoh Resource 23
Contoh Script Radio 24

Penulis Naskah Radio Non Berita - CATATAN SI BRAY 25

Contoh Script Podcast - Pencari Soal 26

Contoh Teks Penyiar Radio – retorika 27

Contoh Teks Penyiar Radio – retorika 28

Contoh Naskah Drama Radio - Contoh Resource 29
32+ Contoh Rancangan Naskah Iklan - Blog Dokumen Gina 30
Contoh Naskah Iklan Radio Lucu - Aneka Contoh 31

Contoh Naskah Radio Berita - Aneka Macam Contoh 32
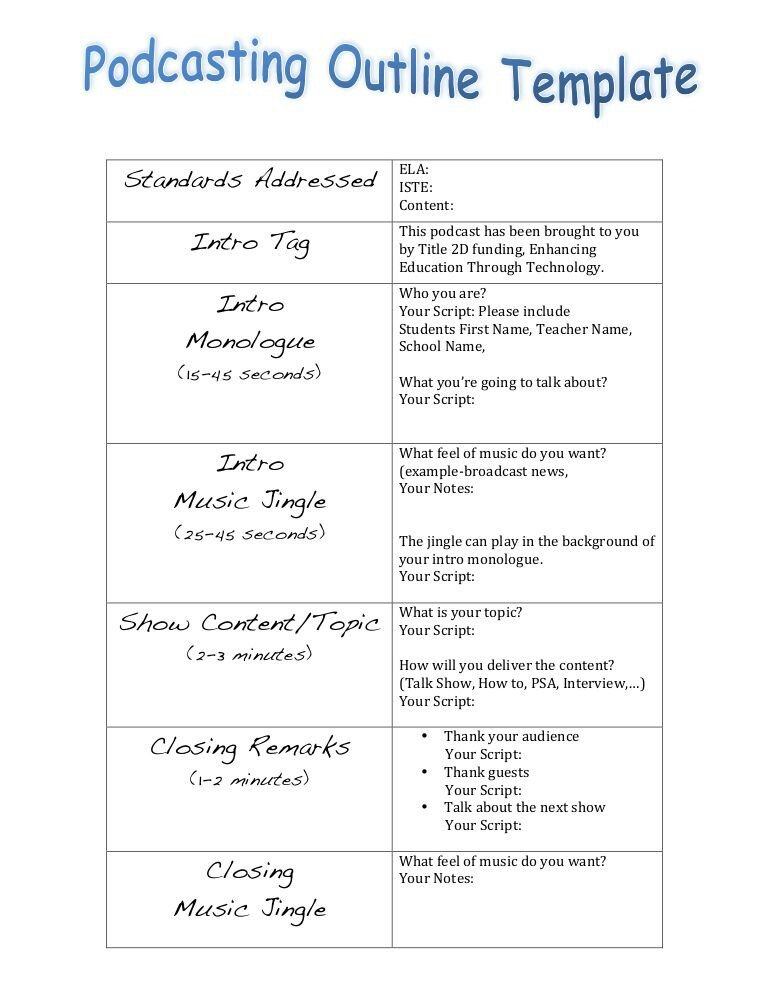
Contoh Script Podcast - Pencari Soal 33

Contoh Script Podcast - Pencari Soal 34
[UPBEAT MUSIC], Rasheed: Hey., And welcome back to the "Made by Google" podcast., I'm your host, Rasheed Finch., And I can't believe this is episode 5 already., We've already covered so much ground in the world of Google hardware., And we have much more to come., So don't forget to subscribe to the podcast., Today, we're talking about talking., Many Google products don't need you to type stuff., Actually, some don't even support typing., But you use your voice, instead., And some products talk back to you, too, most notably,, of course, the Google Assistant., If you ever wondered what's needed to make computers and phones understand, human speech or to make them sound like a human voice,, this is the episode for you because our guest, is the director of product management for Google Speech, Nino Tasca., Nino, welcome to the "Made by Google" podcast., Great to have you., Nino: Thank you for having me., It's great to be here., Rasheed: So you're a director of product management for Google Speech., What do you tell friends and family what it is you do at work?, Nino: Yes., I work on the Google Speech team, which is, really amazing opportunity because at Google, speech is literally, in every product that we produce., And you all know about how many products are out there, with Google, from everything from Search to Google Assistant, YouTube, Cloud,, many more., And what we're seeing is, as speech is getting better at recognizing human, and audio and also synthesizing text, what we call TTS,, there's just many more product opportunities., So it's been a really fun ride to watch how the speech, models get better, technology improves over time,, and more product possibilities emerge., Rasheed: Today's guest works on things that are easy to take for granted,, like talking to your smart speaker and having it talk back to you., As the director of product management for Google Speech,, Nino Tasca actually helps many of our products come to life., Without Google Speech, the Google Assistant simply wouldn't be., And the same goes for the Recorder app or Android features, like Live Caption., Nino will tell you that working on speech technology at Google, is exhilarating because there are so many possibilities to unlock., Each step forward that Nino's team achieves makes computers easier to use., Speech recognition at Google is getting so good that Nino has replaced, a lot of his typing with speaking., Find out much more about Google speech and what, it means to Google's devices and services in this episode, of the "Made by Google" podcast., So you're on a team that makes sure the computer, understands what I say on one side., But on the other side, if I'm, for example, using the Google Assistant,, your team also makes sure that the Google Assistant actually has a way, of saying something that I can hear., Is that right? Nino: Yeah., Exactly., So we think of it as two sides., On the one half, we call it ASR, or Automatic Speech Recognition., And sometimes in the outside world, it's called STT, or Speech-To-Text., So that literally takes speech or audio files, runs it through a speech model,, and then turns that audio into words., So you can think of a Google Assistant query, what's the weather today?, An audio file goes in., And out comes the word "what's the weather today?", And then on the flip side of that, after we determine what the weather actually, is through the Google servers, we actually synthesize and say,, it's sunny and 72 today., And so that word comes through the TTS system, for text-to-speech, so speech-to-text on the input, and text-to-speech on the output., Rasheed: As you said, there are so many products that use speech in one way, or another at Google., I'm just wondering, what's been the most fun to work on in your team?, Nino: It's a great question., Definitely the Google Assistant., We are closely embedded with the Google Assistant, because it brings speech to the forefront., In many of the other products, speech is still, a critical, critical aspect, uncovering many use cases, that were simply not possible before., And we can go into those laters., But with Google Assistant, speech really is at the forefront., And it's been really fun to see how we can build this product that's, a voice-first and really enable use cases, to make things easier for users throughout the day, whether they're, in their house, in the car, or on the go., Rasheed: And speech recognition has been something that scientists, I guess,, or even movie writers have been after for decades and decades., And it's become so good over maybe the past decade., So without asking for a whole lecture, could you explain what happens--, well, let's say when I ask for the weather,, what is happening behind the scenes when I ask that question?, Nino: So you're right., So speech has been a great scientific problem for many decades., As we talked about earlier, we take audio file in., And that comes as audio., And so what's happening is we actually have, deep neural networks that build these machine, learning or speech-to-text models., And it analyzes the audio and determines the words you said., So we actually understand "what's the weather?", Going beyond the speech team then, we actually, have a natural language processing team that, tries to take the intent out of that., So you can see the actual words you said are "what's the weather?", But we now have to translate that into computer code,, which basically says "weather" and maybe the area, you're asking the weather from., If you're on your phone in, let's say, Cleveland, Ohio,, it knows that you want the weather where you are located., So it takes that, sends it to our internal servers,, gets the weather from our system, and then it comes back., And we actually have a generative text writing response engine that, actually formulates the way to say "72 and sunny", in a way that's pleasing to the user., And we switch it up so you're not always hearing, the exact same words and phrases., But on the output, we get that sentence, let's say, "it's 72 and sunny.", And then we actually have to synthesize the text., And that's our TTS engine, which takes those words,, understands the right prosody, the right accent, the right pace of speaking,, and outputs it in a voice that you can select., Rasheed: So what if we back up and go to that speech-to-text situation?, So I think everyone has seen waveforms., That is a way to represent what audio looks like, with these waves going up and down., So how does your team or how does the system make sure that-- or understands, that a certain waveform is maybe the word "weather"?, How do you teach a computer that?, Nino: It's funny because when I joined Google and I was learning about machine, learning, I was also raising my daughter at the same time, whose age, happened to match my tenure at Google., And it's a really similar pattern because what happened many years ago, is we'd actually try to break it up into a couple of milliseconds, of each sound of the word and say OK, "kuh" sounds like K,, and staple them together., And that system is just very, very limited., And the gains have a really low ceiling., But with deep neural networks, we actually, train these models like we train a kid., So if you think about how you teach your kid what certain words are,, you show them a picture of a dog and you say "dog" or "ball.", You don't say "a ball is a round, spherical object, that can be orange for basketball or colored for a beach ball.", You just show them many, many examples., And over time, the brain just gets it., The neural network-- and that's what we actually, call the computer models, neural networks, because they're, modeled after the human brain., And so speech is very similar., We take all these audio samples., And they're just waveforms, like you said., Many people have seen them on a computer before., And then we'll take it and we'll annotate a few of them and said,, this audio says, "what's the weather?", This audio says, "What's your name?", This audio could even be longer., It could be the captioning for a YouTube video., So we take different audio, different use cases,, and throw it into the machine learning model., And the machine learning model recognizes patterns., So when certain audio patterns look like other ones that we know, to be "weather," "the," "Cleveland, Ohio," then we actually can build that, out, extract it, and understand how any input, even input we haven't seen, before, can be translated into text., Rasheed: And I guess it gets a little bit more complicated in practice, because people want to use the Google Assistant maybe when, they're in a busy train station or--, and I don't think I'm going to surprise our listeners here., I'm not a native speaker of English., I suppose for a speech team, that throws in an additional challenge,, to make sure that people like me can also use the Assistant in English., So how do you deal with that?, Nino: That's a great question., So our mission on the Speech team is actually to solve speech for all users,, everywhere., So you bring up two great use cases., One is making sure that everyone, anywhere in the world,, can use speech as well as I can., And that's true if you're speaking your native language., It could be English., It could be a language with less speakers in the world, or it could be someone, like yourself, that wasn't born in a certain country,, but speaks that language maybe with an accent, some stronger than others., And it can also be in difficult environments,, from a train station, when you want to find when, the next train is, or even in the car, with the air conditioning, on, the radio blasting., And so there's all sorts of technology that shoulder, the core speech-to-text system., We have noise cancellation systems in place to make sure that when--, for example, when you're in the car and we know that you're actually, trying to issue a query or a request to the Google Assistant,, we can cancel some of the background noise., And going back to accented speakers, we do make sure we build our speech, models with a wide range of speakers., And one of the things we actually find is getting more realistic use cases, makes for better products and better output., So if we just asked 100 people to say "what's the weather,", we know that it's not going to build a great, great speech, model because it's forced., When someone tells you to read something,, even if you try to do it as natural as possible,, you're not going to say it in the way that people actually use it when it's--, there are two kids in the background eating breakfast and you're running, and you're trying to figure out if I need my rain jacket today., Those are real-life examples., And that's what the Google Assistant needs to be here for,, in those real-life examples., And so the Speech team and all of the teams at Google, work hard to make sure our products work when you need them most,, not just in perfect conditions., Rasheed: All right., So now we know how speech-to-text works., We now know that then there is a server, probably another team, that actually, figures out what the weather is., And then we get back to your team that needs to give the Assistant the voice., So how do you make a computer speak?, Again, that could be a whole lecture, I'm sure., But still wondering, what's the basics there?, Nino: It's funny because it is the same process of deep neural networks, that are trained., For the Google Assistant in English, we actually have 10 different voices., So each of those voices were modeled after a voice, actor, which is a real profession., You, obviously, know this for cartoons or commercial voiceovers., People go into the studio, very high-quality studios,, and can say or utter certain words and phrases., For Google Assistant and many of the other properties out there,, it's a similar process, where we look for actors that have, a certain range of characteristics., And we actually ask them to go into the studio, and say words that the Google Assistant would say-- or Maps, for example--, turn left at the next stoplight., And we-- very similar to what we were talking about with ASR., We don't ask them to say every possible response to the Google Assistant., That, of course, is responsible., But we give them a wide range of text., And then we can feed that into our deep neural networks and output, these TTS voices., So we get the core model, which can take any voice, and make it into a synthetic TTS voice., But then we can actually bring some life to the Google Assistant, by allowing users to choose a voice that best resonates with them., And it's great, too, because we see that users of different groups, like to have voices that sound like them or just is pleasing to their ear., So we find that giving a good choice of voices, actually creates a better user experience, especially, for products like the Google Assistant, where you might use it multiple times, per day, multiple times per week., And so you're building up a relationship with this voice., Rasheed: Cool., So something I'm wondering after speaking, to Monika Gupta in a previous episode-- she works on the Tensor chip--, it's making much of our machine learning available on a Pixel device., And I think that helps creating something, called Assistant Voice Typing, which you're, of course, familiar with--, might be one of your favorite products., So could you explain to us what is Assistant Voice Typing?, And how is it different from maybe all the other Speech products and features, that we've had in the years before? Nino: Yeah., It's great., So yes, you are correct, Assistant Voice Typing, is one of my favorite products and one that our team works on., So let me give you a little bit of history., So dictation has been a feature within Gboard and other email apps, on the phone for many years now, probably over a decade., And it's always worked OK and solved certain use cases., One of the biggest innovations for me just as a user that really turned, it what I call a zero-to-one product--, because when it was first working, it was little bit of lag., You would say a word., And it would take a few seconds or a few milliseconds-- excuse me-- and--, till the words appear on the screen., What we did, though, was we actually invested pretty heavily, to make sure that our speech models, the ones we were just talking about,, can fit on device., And so that's a combination of making the model smaller and also better, hardware., And so now we actually have speech models, high-quality,, that can actually live on your phone., And this is where it turns into a zero-to-one product, because all of the latency, all the lag, goes away., As you're speaking, you can actually see the words appear., And it's really a very interactive product., One of the funny things is in certain use cases,, the words can appear even faster than you say them because we pre-fetch., We know what you're going to say based on the model., So it's one of these little funny twists that the models can do,, is they can predict what you're going to say if you're halfway through a word., So that's been around for a couple of years, as well, on Speech., But with the Pixel, starting with Pixel 6, and then we doubled down on the effort in Pixel 7,, we have these TPU chips, which I believe Monika talked to you about., Rasheed: Yeah., Nino: It really creates these super powerful models, actually, models that are better than models at higher quality, than we can run on the server., And as a product team and an engineering team,, we came together and figured out how can we actually make this a differentiator., And so we invested heavily in making sure that our speech models were, optimized for the chip, everything from high quality, low latency,, low power drain, all of those things., Then we said, OK, what are the real product possibilities?, And we knew with voice dictation, there were still, many rough edges from the old model., You still had to use your hands a lot, everything, from sending to typing certain words or emojis to the To field, the Subject, field., It was still very much--, voice was only part of the experience., And so with Assistant Voice Typing, we wanted, to really make it a full voice-forward experience where you could, actually not need your hands at all., And so that's the model we went into., And so it's funny., People think Speech is just speech-to-text, and getting the words right., There's a lot of other things that go into that., Punctuation matters., Making sure you're spelling and pronouncing the words of loved ones--, so for example, I have a dog named Biscoff,, like the cookie, B-I-S-C-O-F-F, not a common word that's said., So the first time I spoke that in Assistant Voice Typing,, it was recognized as "disc golf," the sport you can play in the park., And one of the features we added with Pixel 7 was this personalization., So now as I tell the Google Assistant and correct "disc golf", into "Biscoff," for every other interaction,, every time I'm texting my wife via Voice--, hey, I'm going to the park to walk Biscoff--, it gets it right., And those things matter., That makes it a usable product because it's as good, and sometimes better,, than what you could do if you were using your fingers, and your thumbs, which I know kids these days are super fast., Voice always beats text, 100% of the time., Rasheed: And that might also be the challenge., People somehow, when it comes to Voice, have super high expectations, that you need to live up to, somehow., So that sort of personalization, where they get the names of loved ones right,, is very important to your team., Nino: Oh, absolutely., Yeah., Rasheed: And we have this section called Made by Numbers in the "Made by Google", podcast where we ask our guest for a number that is either important to them, or in their work., We've had very large numbers., We have smaller numbers., I'm just wondering, what is the number for "Made by Numbers", that you brought to this episode?, Nino: Sure., I'll go with a small number this time, and hopefully smaller, over time, which is 4%., Rasheed: 4%., Nino: So the way we measure speech quality, primarily is called Word Error Rate, or WER for short., And so the way word error rate works is if we're, looking at-- let's say a user says 100 words,, what percentage did we get right?, And what percentage did we get wrong?, And so for certain use cases on the Google Assistant,, especially Assistant Voice Typing, we can, get word error rate down to 4%, which is basically as good as humans can do., And it's really important because, as we've seen throughout Google, as we can, build higher quality speech models, get this word error rate down,, more product possibilities exist., So we've seen all types of products emerge over the last couple of years, once speech quality has risen to the point, where we can basically understand the vast majority of words, that a user is saying., Rasheed: So if it's at 4%, I'm just wondering, is there a class of things, that the system gets wrong, or what's the main reason why it's 4% and not 2%,, for example?, Nino: It's a great question., And obviously, each additional percent gets harder and harder to achieve., So there's a couple of things., One is there's many words in all languages, yes., And so it gets difficult to understand them all., But more importantly, I think it's different environments., Sometimes, in a very clean environment, if a user is talking slowly,, we can get pretty close to 0%., If there's a noisy environment, sometimes that, obfuscates certain words., Sometimes, users even don't speak that clearly., I speak rather fast., And I don't articulate as well., Of course, it's not the user's fault. It's our fault., But it makes it a harder challenge., Sometimes, users have accents or have other difficulty speaking., And it can get harder and harder to understand each individual word., But even for users that--, let's say for our US English model, which, is probably our highest quality one--, users that were born and raised here--, sometimes, they have unique words that just don't match up., It could be a contact name., It could be a street name., It could be the name of a loved one., And those just become extremely hard because they're not used in everyday--, or our models might not have seen those before., So the 4%-- there could be a lot of use cases., We're working on all of those., And some are-- like we mentioned, some of them,, like getting contact names right, is really, really important., Rasheed: So in order to get 4% down, is it, the same as what you mentioned at the beginning,, we just give the system more and more examples, to understand everything better?, Nino: That's not the direction we're going in., We're actually going in an opposite direction,, where we're trying to go into more what's called semi-supervised learning., So we don't have to annotate as many examples., And the deep neural networks can actually just get smarter over time, and learn from audio files that do not actually have--, have been annotated., And so there's many different research efforts underway to get that down., Some of it is pure research, how can we just make the models, faster, better, more efficient., And some are integration points., For example, with Assistant Voice Typing,, we talked about what are your most common contacts,, are there ways to bias to those words, are, there ways to personalize your model to understand certain words better., Going back to the noise in the background, are there more effective, ways to hone in on your voice and your voice, only and cut out the background noise?, So there's many different efforts involved, all working in parallel,, trying to hone in and improve on these models., Rasheed: I think it's so interesting that so many fields come together, in order to solve this problem and not just teaching the model like we, teach kids how to speak., So I wanted to get to my favorite product, which is Recorder., And I can totally see how the Speech model is, used to transcribe what's being said., But now I think later in the year, we're adding, a new feature, where the Recorder app will, be able to distinguish between people., So it can say person 1 says-- said this., And then person 2 said that., What was required to distinguish between voices,, because that seems like a next level of speech recognition to me?, Nino: Yeah., This is another great example of us listening to our users, because the Recorder app has been around for a few iterations with Pixel., And one of the use cases we saw that a lot of journalists, were actually using it--, it was one of their favorite products., We were getting the feedback., And they were actually using it to record and transcribe interviews., But one of the challenges was they had to go back in and separate the voices., So we knew this was actually a very important problem, to solve for some of the most important users that really love this product, and were using it for their critical components of their lives., So in order to detect multiple voices, what the Recorder app does, is actually analyzes the audio., And we can detect different voices that are speaking., Throughout the transcript, we give different labels--, speaker 1, speaker 2., And as each-- as the audio continues, we actually, analyze it from previous versions of speaker 1 or speaker 2, and determine if it's likely that one of those users is speaking., Now, what's important?, Privacy is the utmost importance here., So the models are temporally stored on device, totally, deleted after the session is over., But it provides a really powerful use case that allows you to know--, for example, for a journalist in an interview,, when they're doing transcription, they know what they said., They know what their interviewee said., And they can go back and easily transcribe, the final for post-processing., Rasheed: I think that was-- that's what people always love., You turn on airplane mode., And then still, the Recorder apps works as proof that everything works offline., I guess that also helps some of the Assistant features come to life,, like when it is something like call screening., I guess it's basically the Assistant on the phone answering the phone, right?, It doesn't need a server to do anything else?, Nino: It's great you brought that up., And that's one of my favorite outcomes of working on the Speech team., We've spent a lot of time from a speech perspective,, and primarily leading with the Assistant,, to get speech models on device., And it's great working at a company like Google, because we've seen all this demand internally., And many different teams have now improved, their products to take advantage of this on-device speech models., And we've worked closely with them, once again,, to understand what their exact user needs are,, what the product's needs are, and how we can actually improve our speech models, to make sure their product's better., So I'm just going to list off a few., You have the Call Screen Assistant, which is great., Somebody calls you., Once again, you're busy., It might be a number you don't recognize., And that audio from the user is actually handled 100% on device., We're not sending the audio coming in from a phone call to the servers., And that allows you, the user, to make a decision whether you, want to take that call or not., Let's take Live Caption as another example., With the on-device model, whether you're in airplane mode or not,, any video on your phone--, you can actually see the caption coming through--, great use case, especially if you're in a place, where you can't listen to the audio or you're hearing impaired., Another use case is transcribing messages., Rasheed: That's the one I love. Nino: Yeah., Yeah. It's great., And that's a new feature., So people-- audio voice messages are still very popular., We thought those went away with texting., But they're actually coming back., And so, once again, there's many use cases, where users are in the environment or simply can't listen to the audio file., So the on-device speech-to-text model can actually transcribe the audio, of the message and display it to you--, never needs to go to the server., Rasheed: I always ask all of our guests what's coming in the future., And of course, we cannot talk about future roadmaps., I'm just wondering if you're a speech scientist, as you are, a product, manager who works in this field for so long,, I guess you want to work on dropping the error rate., But what else is there to conquer as a Speech team?, Nino: The opportunities are endless just because there, are so many product possibilities., I'll name a couple., One of the things that I'm really passionate about, is having a personalized model for every user on their device., We talked about the big investments to get on-device speech., We've talked a bit about personalization, especially in the use, cases for Assistant Voice Typing., But we actually want to make personalized model that understand, how you speak, your pace of speech, the words you say most commonly, accents,, et cetera, and actually make a model that can be tuned on the fly, make sure each time you talk and the more you talk,, it gets better and better for you., We have a great example of personalization in use today, with Project Relate, which allows users with speech difficulties, to actually train their own personalized models, by saying several different utterances and phrases into their phone., The model gets 100% built and personalized for them and enables, and opens up all kinds of use cases that these users might not have access, to today, everything from using the Google Assistant,, taking notes, or even having a repeat function, where, let's say if you're in line for Starbucks,, the cashier can't understand you, you can say your order to the phone,, and it can repeat back in our text-to-speech output., So I can imagine the Project Relate technology being, expanded to all users in the future., And then with making a personalized model, it's not just about your speech., But other things we're looking at is multilingual models., A very large percentage of the world actually speaks more than one language., And we want Speech to be there for you in any use case you need., So going back to Assistant Voice Typing, people that speak multiple language,, they might speak to one group of friends in, let's say,, English, another group of friends in French., And they shouldn't have to think or understand which Speech model to use., They should just be able to talk freely., And we want to build multilingual models that can just, understand them naturally as they go., And final point would just be natural conversations in general., This is a big project we're working on for the Google Assistant,, is making sure that we actually have a better way to have, natural back-and-forth conversations., Today, the Google Assistant is still very much in a turn-taking approach,, where you have to say, hey, Google, what's the weather,, and wait for it to come back., But we realize that's not how humans have conversations., There's pauses., You just did "mm-hmm.", Rasheed: That's right., Nino: There's the back-and-forth with a back channeling., There is interrupting., Sometimes, it can be polite., It's just the way conversations go., And we want to make sure the Assistant is usable, just, like you're talking to your friend., You don't need instructions., You don't need to do turn-taking in order to make it work., You can just talk., You can have a natural pause., You can get some feedback from the Google Assistant., You can interrupt it-- and no instructions, needed to use the Google Assistant., So all those three things are things that I'm really, really excited about, and, hopefully, you'll see in future product updates., Rasheed: So Nino, finally, we always have the Top Tips for the Road,, where we ask our guests what are our top tips for our listeners, to the "Made by Google" podcast?, This could be tips, in your case, about speech, or maybe it's life advice., I don't know., [UPBEAT MUSIC], What are the Top Tips for the Road?, What should we take away?, Nino: Sure., So I'll give you just one work advice I find really, powerful and then one speech advice., Rasheed: Sure., Nino: One of the things I think is really important is schedule send., So you can see that in email nowadays., I just think it's really important as--, since the pandemic, our work and home lives are more intertwined., A lot of people have setups in their desks at their-- in their house., And it can never stop., And I think being a responsible leader, a responsible teammate, making sure, if you decide to work at night or on the weekend,, you're not putting pressure on others., And so what I do is, if I decide to work on the weekends,, I make sure I schedule send to Monday morning, so I'm not putting pressure on users., It's a great feature in Gmail., And I just encourage everyone to use that to be more, thoughtful of how we work together., So that's just a general tip., Rasheed: Great advice., Absolutely., Nino: But then sticking with email and messaging, try the voice dictation., I think many users have tried it over the past., But maybe you had an ear., Maybe you had a-- one use case which didn't work., There's just a ton of innovation going on there., There is a ton of effort., We actually have data that shows it's 2.5 times, faster than using your fingers to type., And so if you had a bad experience, give it another shot., If you have a bad experience, give it another shot again., The teams are constantly working., And now, as a user myself, who uses it almost exclusively when I'm able to,, it's such a powerful, powerful tool., And I hope all users try it and keep testing it out and give us feedback., The best way we can build products is to get feedback from users, that are actually using the product., Rasheed: Noted., And I use it, as well, myself and love using it., And just for everyone listening, to go back to Project Relate,, please just Google that, Project Relate., It's a beautiful thing., And it just shows how your team helps a lot of people, have a better opportunity in communicating, with others in this world., So thank you a lot for that., And also, thanks so much for joining the "Made by Google" podcast., It was great talking to you. Nino: My pleasure., Thank you., [UPBEAT MUSIC], Rasheed: Well, I can't tell you often enough,, do check out Project Relate when you have a chance., It really shows a powerful side of technology, and how it helps make it easier for anyone to be a full part of society., And thank you to Nino for your time today-- been great to find out, how we make our devices able to understand what, you say and then even talk back to you., Join us next week for another episode of the "Made by Google" podcast,, where we'll talk about fitness., So I better get ready and in shape., And meanwhile, subscribe to the podcast so you'll, have the latest episode on your device when it appears each Thursday., Take care., Stay healthy., Talk to you next week.